UUID v7 vs v4: why random primary keys wreck your index
published
TL;DR
A UUID v4 is 122 random bits, so consecutive inserts land at random positions in your primary-key index. On a clustered-index engine (InnoDB, SQL Server) that means constant page splits and a buffer pool full of pages you’ll never touch again. UUID v7 puts a millisecond timestamp in the high bits, so new rows sort to the right edge of the index and inserts append instead of scatter. If you generate IDs in the application and store them as a 16-byte binary key, switch v4 → v7.
The problem
The two UUIDs people reach for look interchangeable:
v4: 9f1a2b3c-4d5e-4f60-8a7b-1c2d3e4f5a6b (122 random bits)
v7: 0192a4f7-8c21-7b3e-9d44-5e6f7a8b9c0d (48-bit ms timestamp + random)crypto.randomUUID() in browsers and Node, uuid_generate_v4() in old Postgres setups, and most ORMs’ default all hand you v4. It’s random by design — great for uniqueness without coordination, terrible for being a primary key.
The symptom shows up once the table outgrows RAM: insert throughput falls off a cliff, write amplification climbs, and the index bloats to a fraction of its theoretical fill. The table isn’t bigger than your disk — it’s that your hot working set is the entire index instead of its right edge.
Why it happens
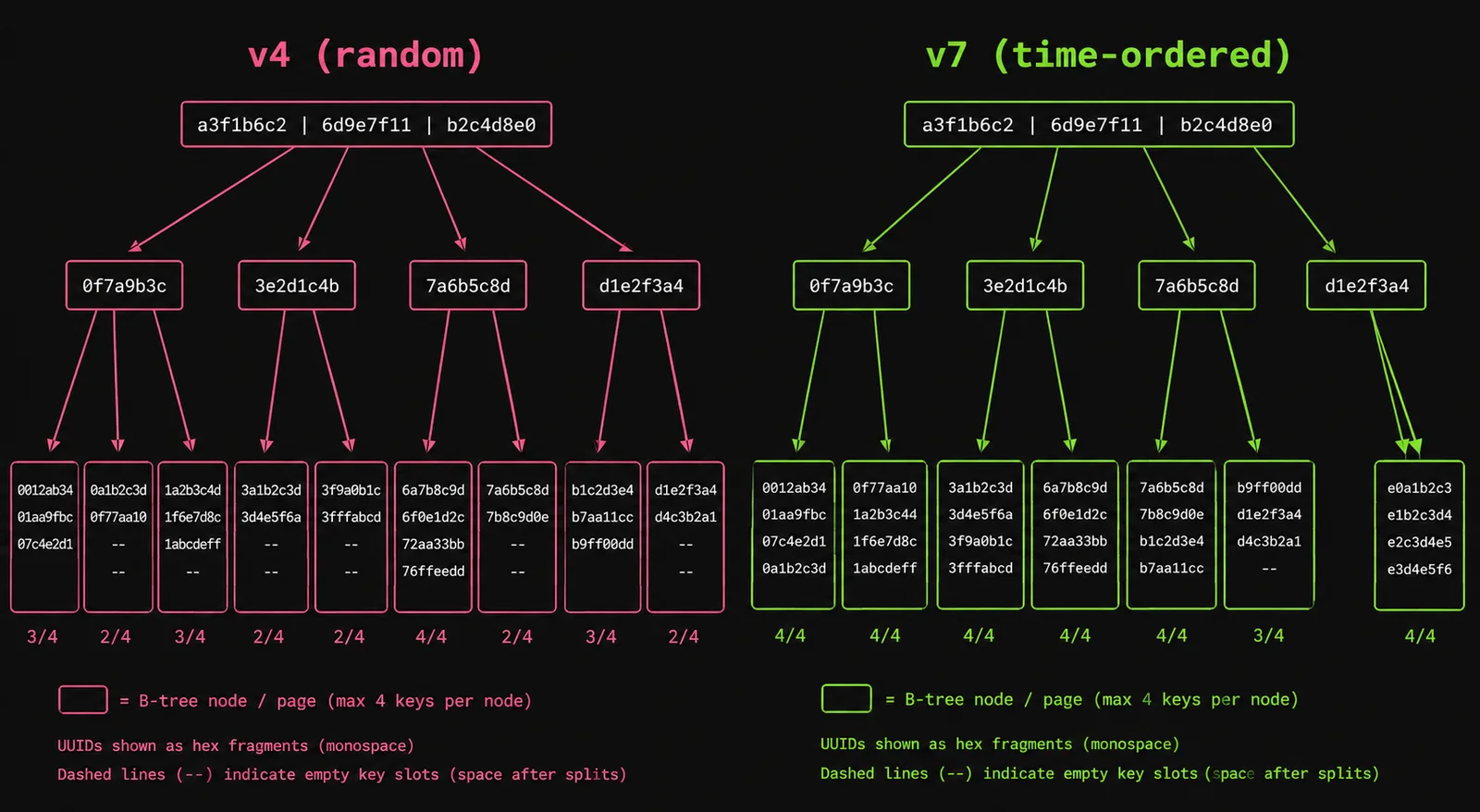
A B-tree index keeps keys sorted. Where a new key lands depends entirely on its value:
- Time-ordered key (v7, v6, ULID, auto-increment): every new value is larger than the last, so it goes into the right-most leaf page. That page stays hot in cache, fills up, splits once, and you move on. Sequential, predictable, cache-friendly.
- Random key (v4): the next value is equally likely to belong anywhere. The leaf page it targets is probably not in cache, so the engine reads it in, modifies it, and likely evicts something you’ll need soon. When a randomly-targeted page is full, it splits — and random inserts cause splits everywhere, leaving leaf pages roughly half empty.
How much this hurts depends on whether the UUID is the clustered key (the table rows themselves are stored in PK order) or just a secondary B-tree index next to a heap:
| Engine | PK storage | Random UUID PK impact |
|---|---|---|
| MySQL / MariaDB (InnoDB) | Clustered — rows live in the PK B-tree | Worst case. Every insert may relocate row data; page splits fragment the whole table; secondary indexes store the fat PK, multiplying the cost. |
| SQL Server | Clustered by default on the PK | Same clustered-index fragmentation. NEWID() is the classic offender; NEWSEQUENTIALID() exists precisely to dodge it. |
| PostgreSQL | Heap table + separate PK B-tree | Milder — row data goes to the heap, but the index still takes random inserts: more buffer churn and more full-page WAL writes after each checkpoint. |
The other tax is full-page writes. After a checkpoint, the first modification to a page is logged in full to the write-ahead log to survive torn writes. Random inserts touch many distinct pages between checkpoints, so you log many full pages; sequential inserts keep hammering the same right-edge page, so you log it once.
What to do
Use v7 for new tables. It’s part of RFC 9562 (May 2024, which obsoletes RFC 4122 and standardizes v6/v7/v8). Layout: 48-bit Unix-epoch millisecond timestamp, then version/variant bits, then random fill — so it’s monotonic at millisecond granularity and still has 74 bits of randomness for uniqueness within a millisecond.
Generate it where you create the row:
// Browser/Node: crypto.randomUUID() is v4-only, so generate v7 explicitly.
// npm i uuid (v9+)
import { v7 as uuidv7 } from 'uuid';
const id = uuidv7(); // "0192a4f7-8c21-7b3e-9d44-5e6f7a8b9c0d"Or let the database do it. PostgreSQL 18 ships a native function:
-- PostgreSQL 18+
CREATE TABLE event (
id uuid PRIMARY KEY DEFAULT uuidv7(),
body jsonb NOT NULL
);Store it as 16 bytes, not 36-char text. A CHAR(36) UUID is 36 bytes plus it sorts as text and inflates every secondary index. Use the native uuid/UNIQUEIDENTIFIER type (16 bytes).
If you’re stuck on v1 in MySQL, the bytes are time-ordered but in the wrong field order. UUID_TO_BIN(uuid, 1) swaps the time fields so the binary value sorts chronologically — see the MySQL function reference. For v7 you don’t need the swap; its bytes are already in sort order.
Don’t rewrite a working v4 table just to chase this. The win is on insert-heavy tables large enough to blow past the buffer pool. A small or read-mostly table won’t notice.
Caveats
- v7 leaks creation time. The timestamp is recoverable from the ID to the millisecond. If a primary key is exposed in URLs or APIs and creation time is sensitive, that’s an information leak — keep v4 (or a separate opaque ID) for the public-facing identifier.
- Monotonicity is per-generator, not global. Two app servers generating v7s in the same millisecond can interleave; you get approximately sorted, not strictly sorted. That’s enough for index locality, not enough to treat the ID as a global sequence.
- ULID is a fine alternative with the same time-ordered property and Crockford base32 text encoding (spec), but it’s not an RFC and not a native DB type — you store it as text or as a 16-byte blob yourself.
- Auto-increment integers still win on raw size and locality. v7 is the answer when you specifically want UUIDs (client-side generation, no round-trip to get an ID, no cross-shard collisions) without paying the random-insert tax.
References
- RFC 9562 — Universally Unique IDentifiers (UUIDs) — the v7 layout is in §5.7
- PostgreSQL 18 UUID functions — native
uuidv7()/uuidv4() - MySQL UUID_TO_BIN / BIN_TO_UUID — the time-field swap flag
- Percona — storing UUIDs the optimized way — InnoDB clustered-index insert benchmarks
- MDN — Crypto.randomUUID() — confirms it returns v4
- ULID specification